1 项目需求
1)需求
- 统计今天到目前为止的访问量
- 统计今天到目前为止从搜索引擎过来的课程的访问量
2)开发环境与技术选型
- IDEA+maven
- flume+kafka+HBase
3)安装配置 HBase
- 下载、解压、配置环境变量
- 配置文件
conf/hbase-env.sh
修改JAVA_HOMEexport HBASE_MANAGES_ZK=falseconf/hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>hdfs://localhost:8020/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>localhost:2181</value></property></configuration>conf/regionservers
localhost4)HBase 建表
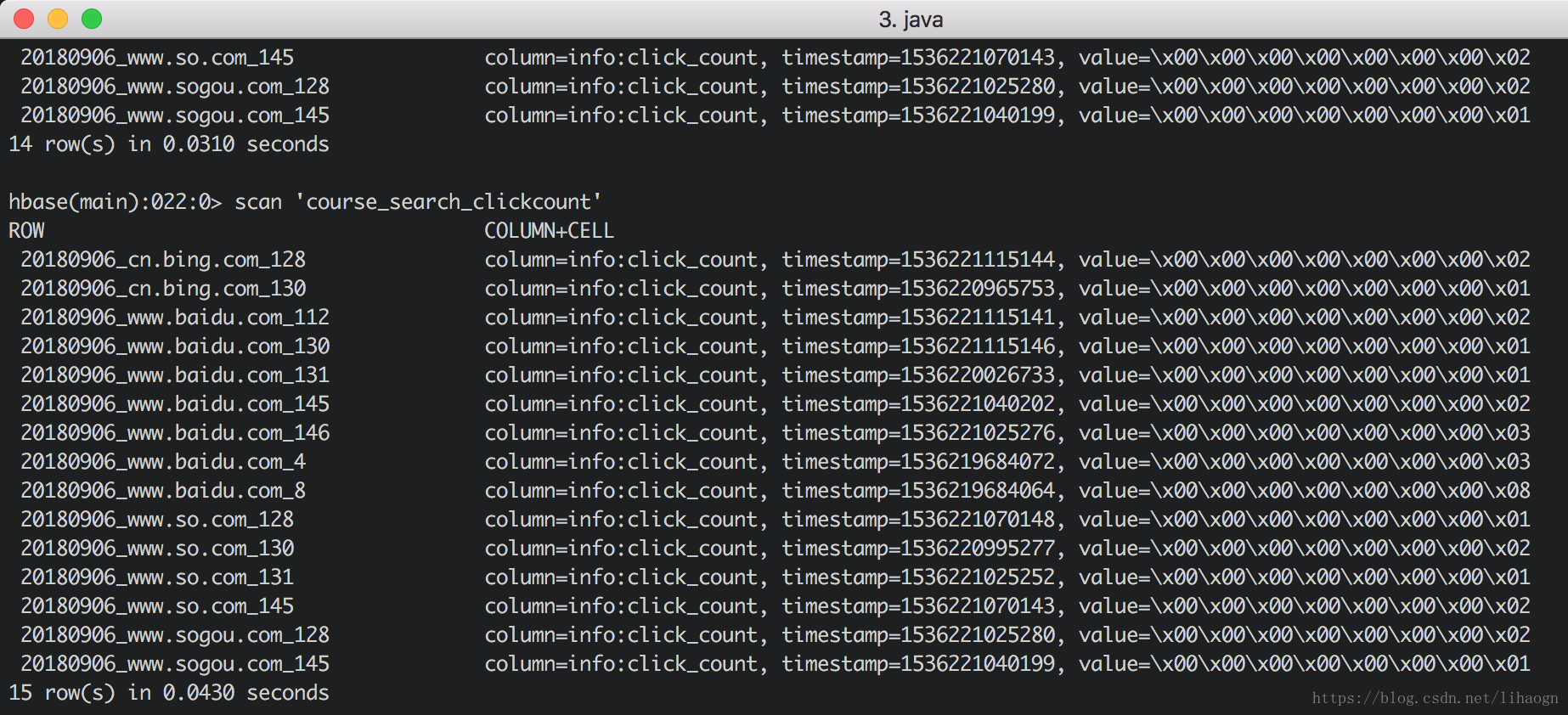
//1 启动hbase start-hbase.sh // 2 启动shell hbaseshell // 3 建表create'course_clickcount','info'create'course_search_clickcount','info' // 4 查看数据表 list // 5 查看数据表信息 describe'course_clickcount' // 6 查看表数据 scan'course_clickcount'5)代码地址
2 模拟日志生成
1)使用python开发日志生成器模拟产生日志,每分钟产生一次日志信息
generate_log.py
#coding=UTF-8import randomimport time url_paths=["class/112.html","class/128.html","class/145.html","class/130.html","class/146.html","class/131.html","learn/821","course/list" ] ip_slices=[132,156,124,10,29,167,143,187,30,46,55,63,72,87,98,168] http_referers=["https://www.baidu.com/s?wd={query}","https://www.sogou.com/web?query={query}","https://cn.bing.com/search?q={query}","https://www.so.com/s?q={query}" ] search_keyword=["spark sql实战","hadoop 基础","storm实战","spark streaming实战" ] status_code=["200","404","500"]defsample_status_code():return random.sample(status_code,1)[0]defsample_referer():if random.uniform(0,1)>0.2:return"-" refer_str=random.sample(http_referers,1) query_str=random.sample(search_keyword,1)return refer_str[0].format(query=query_str[0])defsample_url():return random.sample(url_paths,1)[0]defsample_ip(): slice=random.sample(ip_slices,4)return".".join([str(item)for itemin slice])defgenerate_log(count=10): time_str=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) f=open("/Users/Mac/testdata/streaming_access.log","w+")while count >=1: query_log="{ip}\t{local_time}\t\"GET /{url} HTTP/1.1\"\t{status_code}\t{refer}".format(url=sample_url(),ip=sample_ip(),refer=sample_referer(),status_code=sample_status_code(),local_time=time_str) print(query_log) f.write(query_log+"\n") count=count-1if __name__ =='__main__':# 每一分钟生成一次日志信息whileTrue: generate_log() time.sleep(60)3 flume收集日志并对接kafka
1)编写flume配置文件,streaming_project2.conf
exec-memory-kafka.sources= exec-source exec-memory-kafka.sinks=kafka-sink exec-memory-kafka.channels= memory-channel exec-memory-kafka.sources.exec-source.type=exec exec-memory-kafka.sources.exec-source.command=tail-F /Users/Mac/testdata/streaming_access.log exec-memory-kafka.sources.exec-source.shell= /bin/sh-c exec-memory-kafka.memory-channel.type=memory exec-memory-kafka.sinks.kafka-sink.type= org.apache.flume.sink.kafka.KafkaSink exec-memory-kafka.sinks.kafka-sink.brokerList=localhost:9092 exec-memory-kafka.sinks.kafka-sink.topic=test_topic exec-memory-kafka.sinks.kafka-sink.batchSize=5 exec-memory-kafka.sinks.kafka-sink.requireedAcks=1 exec-memory-kafka.sources.exec-source.channels=memory-channel exec-memory-kafka.sinks.kafka-sink.channel= memory-channel4 业务开发
4.1 消费kafka数据、数据清洗与统计
1)实体类
ClickLog.scala
package com.lihaogn.sparkProject.domain/** * 清洗后的日志格式 * *@param ip *@param time *@param courseId *@param statusCode 日志访问状态码 *@param referer */caseclassClickLog(ip: String, time: String, courseId: Int, statusCode: Int, referer: String)CourseClickCount.scala
package com.lihaogn.sparkProject.domain/** * 课程点击次数实体类 * *@param day_course 对应HBase中的rowkey *@param click_count 访问次数 */caseclassCourseClickCount(day_course: String, click_count: Long)CourseSearchClickCount.scala
package com.lihaogn.sparkProject.domain/** * 从搜索引擎过来的课程点击数实体类 *@param day_search_course *@param click_count */caseclassCourseSearchClickCount(day_search_course: String, click_count: Long)2)工具类
DateUtils.scala
package com.lihaogn.sparkProject.utilsimport java.util.Dateimport org.apache.commons.lang3.time.FastDateFormat/** * 日期时间工具类 */objectDateUtils {val OLD_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")val TARGET_FORMAT = FastDateFormat.getInstance("yyyyMMddHHmmss")def getTime(time: String) = { OLD_FORMAT.parse(time).getTime }def parseToMinute(time: String) = { TARGET_FORMAT.format(new Date(getTime(time))) }def main(args: Array[String]): Unit = { println(parseToMinute("2018-9-6 13:58:01")) } }添加依赖
<!-- cloudera repo--><repositories><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos</url></repository></repositories><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><!-- hadoop --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency>HBaseUtils.java
package com.lihaogn.spark.project.utils;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.client.HBaseAdmin;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;/** * HBase操作工具类,Java工具类建议采用单例模式封装 */publicclassHBaseUtils { HBaseAdmin admin =null; Configuration configuration =null;/** * 私有构造方法 */privateHBaseUtils() { configuration =new Configuration(); configuration.set("hbase.zookeeper.quorum","localhost:2181"); configuration.set("hbase.rootdir","hdfs://localhost:8020/hbase");try { admin =new HBaseAdmin(configuration); }catch (IOException e) { e.printStackTrace(); } }privatestatic HBaseUtils instance =null;publicstaticsynchronized HBaseUtilsgetInstance() {if (null == instance) { instance =new HBaseUtils(); }return instance; }/** * 根据表名获取到HTable实例 * * @param tableName * @return */public HTablegetTable(String tableName) { HTable table =null;try { table =new HTable(configuration, tableName); }catch (IOException e) { e.printStackTrace(); }return table; }/** * 添加一条记录到表中 * * @param tableName * @param rowkey * @param cf * @param column * @param value */publicvoidput(String tableName, String rowkey, String cf, String column, String value) { HTable table = getTable(tableName); Put put =new Put(Bytes.toBytes(rowkey)); put.add(Bytes.toBytes(cf), Bytes.toBytes(column), Bytes.toBytes(value));try { table.put(put); }catch (IOException e) { e.printStackTrace(); } }publicstaticvoidmain(String[] args) {// HTable table = HBaseUtils.getInstance().getTable("course_clickcount");// System.out.println(table.getName().getNameAsString()); String tableName ="course_clickcount"; String rowkey ="20180906_1"; String cf ="info"; String column ="click_count"; String value ="2"; HBaseUtils.getInstance().put(tableName, rowkey, cf, column, value); } }3)数据库操作
CourseClickCountDAO.scala
package com.lihaogn.sparkProject.daoimport com.lihaogn.spark.project.utils.HBaseUtilsimport com.lihaogn.sparkProject.domain.CourseClickCountimport org.apache.hadoop.hbase.client.Getimport org.apache.hadoop.hbase.util.Bytesimport scala.collection.mutable.ListBuffer/** * 数据访问层,课程点击数 */objectCourseClickCountDAO {val tableName ="course_clickcount"val cf ="info"val qualifer ="click_count"/** * 保存数据到HBase * *@param list */def save(list: ListBuffer[CourseClickCount]): Unit = {val table = HBaseUtils.getInstance().getTable(tableName)for (ele <- list) { table.incrementColumnValue(Bytes.toBytes(ele.day_course), Bytes.toBytes(cf), Bytes.toBytes(qualifer), ele.click_count) } }/** * 根据rowkey查询值 *@param day_course *@return */def count(day_course:String):Long= {val table = HBaseUtils.getInstance().getTable(tableName)val get =new Get(Bytes.toBytes(day_course))val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)if (value ==null) {0L }else Bytes.toLong(value) }def main(args: Array[String]): Unit = {val list=new ListBuffer[CourseClickCount] list.append(CourseClickCount("20180906_8",8)) list.append(CourseClickCount("20180906_4",3)) list.append(CourseClickCount("20180906_2",2)) save(list) println(count("20180906_8")+":"+count("20180906_4")+":"+count("20180906_2")) } }CourseSearchClickCountDAO.scala
package com.lihaogn.sparkProject.daoimport com.lihaogn.spark.project.utils.HBaseUtilsimport com.lihaogn.sparkProject.domain.{CourseClickCount, CourseSearchClickCount}import org.apache.hadoop.hbase.client.Getimport org.apache.hadoop.hbase.util.Bytesimport scala.collection.mutable.ListBuffer/** * 数据访问层,从搜索引擎过来的课程点击数 */objectCourseSearchClickCountDAO {val tableName ="course_search_clickcount"val cf ="info"val qualifer ="click_count"/** * 保存数据到HBase * *@param list */def save(list: ListBuffer[CourseSearchClickCount]): Unit = {val table = HBaseUtils.getInstance().getTable(tableName)for (ele <- list) { table.incrementColumnValue(Bytes.toBytes(ele.day_search_course), Bytes.toBytes(cf), Bytes.toBytes(qualifer), ele.click_count) } }/** * 根据rowkey查询值 * *@param day_search_course *@return */def count(day_search_course: String): Long = {val table = HBaseUtils.getInstance().getTable(tableName)val get =new Get(Bytes.toBytes(day_search_course))val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)if (value ==null) {0L }else Bytes.toLong(value) }def main(args: Array[String]): Unit = {val list =new ListBuffer[CourseSearchClickCount] list.append(CourseSearchClickCount("20180906_www.baidu.com_8",8)) list.append(CourseSearchClickCount("20180906_www.baidu.com_4",3)) save(list) println(count("20180906_www.baidu.com_8") +":" + count("20180906_www.baidu.com_4")) } }4)主类
SparkStreamingApp.scala
packagecom.lihaogn.sparkProject.main importcom.lihaogn.sparkProject.dao.{CourseClickCountDAO, CourseSearchClickCountDAO} importcom.lihaogn.sparkProject.domain.{ClickLog, CourseClickCount, CourseSearchClickCount} importcom.lihaogn.sparkProject.utils.DateUtils import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.kafka.KafkaUtils import scala.collection.mutable.ListBuffer/** * 使用spark streaming分析日志 */ object SparkStreamingApp { def main(args: Array[String]): Unit = { if (args.length !=4) { System.err.println("usage: KafKaReceiverWC <zkQuorum> <group> <topics> <numThreads>") } val Array(zkQuorum, group, topics, numThreads) = args val sparkConf = new SparkConf().setAppName("SparkStreamingApp").setMaster("local[5]") val ssc = new StreamingContext(sparkConf, Seconds(5)) val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap // spark streaming 对接 kafka val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap) // 步骤一:测试数据接收 messages.map(_._2).count().print() // 步骤二:数据清洗 val logs = messages.map(_._2) val cleanData = logs.map(line => { val infos = line.split("\t") val url = infos(2).split(" ")(1) var courseId =0 // 获取课程标号 if (url.startsWith("/class")) { val courseHtml = url.split("/")(2) courseId = courseHtml.substring(0, courseHtml.lastIndexOf(".")).toInt } ClickLog(infos(0), DateUtils.parseToMinute(infos(1)), courseId, infos(3).toInt, infos(4)) }).filter(clicklog => clicklog.courseId !=0) cleanData.print() // 步骤三:统计今天到现在为止的课程访问量 cleanData.map(x=>{ (x.time.substring(0,8)+"_"+x.courseId,1) }).reduceByKey(_+_).foreachRDD(rdd=>{ rdd.foreachPartition(partitionRecords=>{ val list=new ListBuffer[CourseClickCount] partitionRecords.foreach(pair=>{ list.append(CourseClickCount(pair._1,pair._2)) }) // 写入数据库 CourseClickCountDAO.save(list) }) }) // 步骤四:统计从搜索引擎过来的从今天开始到现在的课程的访问量 cleanData.map(x=>{ val referer=x.referer.replaceAll("//","/") val splits=referer.split("/") var host="" if(splits.length>2) { host=splits(1) } (host,x.courseId,x.time) }).filter(_._1!="").map(x=>{ (x._3.substring(0,8)+"_"+x._1+"_"+x._2,1) }).reduceByKey(_+_).foreachRDD(rdd=>{ rdd.foreachPartition(partitionRecords=>{ val list =new ListBuffer[CourseSearchClickCount] partitionRecords.foreach(pair=>{ list.append(CourseSearchClickCount(pair._1,pair._2)) }) // 写入数据库 CourseSearchClickCountDAO.save(list) }) }) ssc.start() ssc.awaitTermination() } }5 运行测试
1)启动 zookeeper
zkServer.shstart2)启动 HDFS
start-dfs.shstart-yarn.sh3)启动 kafka
kafka-server-start.sh-daemon$KAFKA_HOME/config/server.properties $4)启动 flume
flume-ng agent \ --conf$FLUME_HOME/conf \--conf-file$FLUME_HOME/conf/streaming_project2.conf \--name exec-memory-kafka \-Dflume.root.logger=INFO,console5)运行日志生成器
python3 generate_log.py6)运行spark程序
spark-submit \ --classcom.lihaogn.sparkProject.main.SparkStreamingApp \--master local[5] \--nameSparkStreamingApp \--jars /Users/Mac/software/spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar,$(echo /Users/Mac/app/hbase-1.2.0-cdh5.7.0/lib/*.jar | tr' '',') \/Users/Mac/my-lib/Kafka-train-1.0.jar \ localhost:2181 test test_topic 17)结果